POSTS
How to create a static website using Hugo, host it on AWS S3, and have it auto-deploy
UPDATE May 8 2020: Since writing this post, I have discovered that AWS offers a simplified deployment process called Amplify Console. Setting up a deployment pipeline for one of the supported platforms (including hugo) is much more straightforward, and you end up with exactly the same result. While what I document here is still valid, I would recommend looking at Amplify Console instead. As with all “magic” solutions, Amplify console won’t be quite as flexible as a full pipeline built yourself (for example, no Lambda@Edge), but it will be a lot easier to manage. One little caveat - make sure you check the build settings if you are passing in any environment variables like HUGO_ENV - You might need to edit it (Which is easy to do in the console) if you need to pass them in.
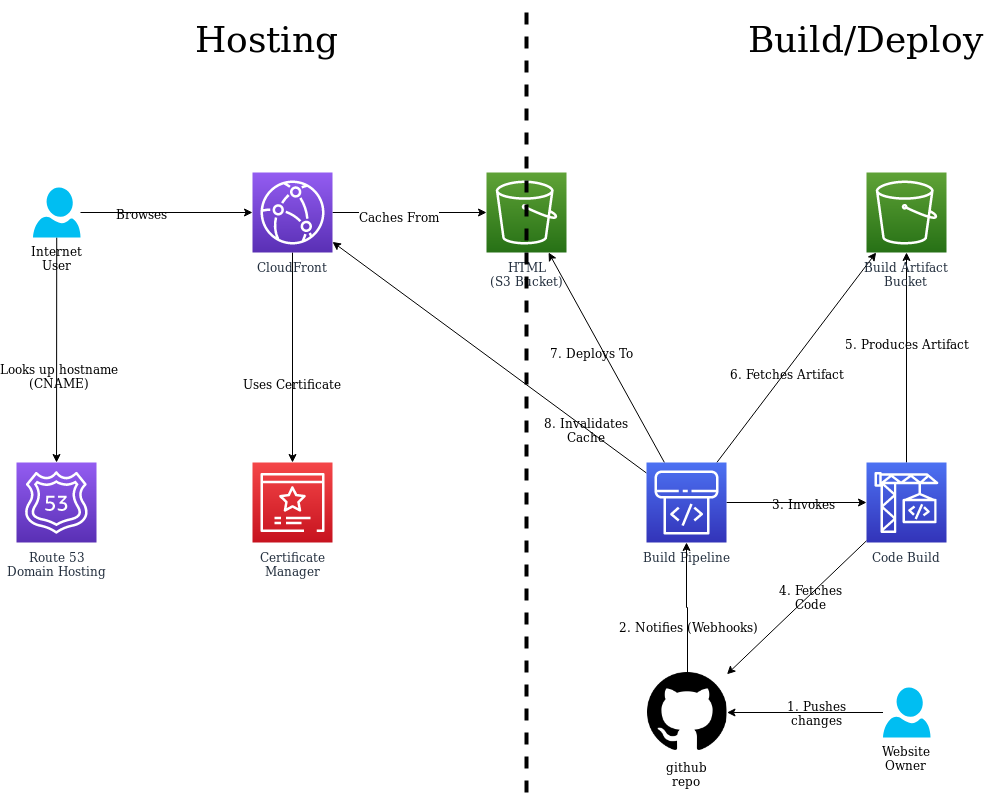
I spent this weekend resurrecting my website. I ported it to hugo, using a stock theme, and replaced all the old embedded flash players with their modern equivalents. Once this was done, I needed a place to host the code, as well as a stable mechanism of getting changes out. I’m going to outline the hosting and build system I have chosen to use. This approach is suitable for any statically generated website, and will be very cost effective to run (on the order of cents per month).
There’s two aspects to this. The first is setting up hosting. The second is automating the build and deployment process. I’m going to use AWS1 to host the content and perform the builds. There are equivalent tools from other providers.
Creating the website
I have pretty simple needs in a website. All I really need is:
- HTTPS to be enabled (major browsers are now requiring HTTPS)
- My own domain
- It should be fast
- Low running costs (including the certificates)
- Not to have to worry about patching and upgrading
Wordpress is nice, but there’s a lot of code involved. This needs to run on a server, with a database, and you need to make sure that all stays up and patched. Its a big headache. Instead, many people turn to creating a static website that is generated each time you create new content, then you can simply upload that to a hosting provider.
There are many choices for frameworks. I have chosen to go with hugo as it is fast, easy to use, and has some sensible default templates that you can work with. Creating a basic website is as simple as following the Quickstart. Once you’ve finished creating some content, running the hugo command will output your website to the public directory on your host. Now all you need to do is host them somewhere
Hosting
AWS has a service called Simple Storage Service, or S3 for short. With this, you can simply create a bucket and upload your content, turn on a few configuration options, then you’ve got a website.
- Sign in to the AWS console. If you don’t have an account, you can sign up easily here
- Choose a region that you want to host your content in. Your website will be available globally, but the source HTML needs to live somewhere. Choose a region that is close to you. I chose Sydney.
- Use the Services menu up the top left to select S3
- Press the “Create Bucket” button
- Give your bucket a name. It doesn’t really matter what the name of this bucket is, only you will ever see it. Press
next. - Configure any options that you want. I was happy with the defaults, so I just pressed
nextto skip this step - By default, buckets are created so that only you can access them. In this circumstances, we want to open the bucket to the world (read only). In the permissions tab, deselect the “block all public access” option, and proceed to the review screen
- One last click, and you have a bucket.
- Upload your HTML by dragging and dropping the files onto the browser, or using the aws-cli once you’ve set up local credentials.
aws s3 sync public s3://yourbucket/ - Now you have your files stored on S3, but we haven’t made the bucket public yet. Even though we turned off “block all public access” before, its still locked down by default.To do this, we select the permissions tab, then click on “Bucket Policy”. This will bring up an editor that allows you to specify what the access rules are for the bucket. Put the following text in there, making sure to replace
BUCKETNAMEwith your own bucket.{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadGetObject", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::BUCKETNAME/*" } ] } - Now anyone can get (but not add/modify/delete or list) all the files in your bucket. The files will be available at a URL that will be something like http://brucecooper.net.s3-ap-southeast-2.amazonaws.com/index.html (with your bucket name and region substituted). Its not a website yet, however. It does not handle index files properly, nor does it provide any error handling. To make this work properly, we need to turn on static website hosting in the properties tab. Switch to the properties tab, then click on “Static website hosting”. Select “Use this bucket to host a website”, type in
index.htmlfro the index document, then click on save. - The website is now live, but at a slightly different URL. In my case its http://brucecooper.net.s3**-website**-ap-southeast-2.amazonaws.com/. See the little
-websitebit that it added in there? That is the difference between getting the hosting of index files right or not. I was fooled for several hours by this, especially as its not easy to spot.
So now you have a website, but its on a big long URL that doesn’t look nice, next we’re going to hook it up to our own domain and turn on HTTPS/SSL.
Adding your own Domain and SSL
S3 doesn’t support custom domain names or SSL. To add these we need to turn to CloudFront. Cloudfront is a Content Distribution Network, or CDN, that speeds up websites by caching content in dozens of locations all around the world so that when people look up your content it will be delivered as quickly as possible. But before we set that up we need to create a SSL certificate for the website.
First up, lets create a certificate. AWS manages all the certificate rotation for you, making it more secure and more hassle free. Even better, the certificates are free!
- I’m assuming you’ve already registered your domain, and that you have the ability to make changes to it. If not, you can register your domain with Route53.
- Head back to the AWS console, and select “Certificate Manager” from the “security, Identity, & Compliance” section. I find its easier to type the name of the service into the little search bar than it is to find the service in the sea of services in the list
- Click on the “Provision Certificates” get started button, or the “Request a certificate” button if there are existing certificates
- Choose “Request a public certificate”
- Enter all of the domain names you want this certificate to be for, as well as variants. As an example, I put in the following
- www.brucecooper.net
- brucecooper.net
- www.8bitcloud.com
- 8bitcloud.com
- Choose your method of domain validation - I chose DNS validation. Click on Review, then Confirm and request
- Perform the required validation steps.
Now we’ve got a certificate, we can move on to creating the cloudfront distribution.
- Navigate to “Cloudfront” in the “Networking & Content Delivery” section
- Click on “Create Distribution”.
- Select “Web”
- When you click on “Origin Domain name”, it will helpfully show you a drop down of all of your buckets to use as a source. DO NOT SELECT ONE, as this will use the S3 endpoint, not the website endpoint. As a result, you will not get the index file delivery that was discussed above. Instead, type in the fully qualified domain name of the website, including the
-websitepart. in my case, I used brucecooper.net.s3-website-ap-southeast-2.amazonaws.com. - Select “Redirect HTTP to HTTPS” - That way you’ll be participating in the HTTPS only campaign that is currently underway around the internet
- By default, CloudFront caches content for 24 hours. This is good and will make your website super fast, but it can cause confusion when you’re starting out. If you want to, change the maximum TTL and default TTL to 0 to disable caching.
- In the Distribution Settings, add all of the host names you want to use in the CNAMEs section.
- Select “Custom SSL Certificate”, then select your certificate from the drop down
- All other configuration values can be left as they are. Click on “Create Distribution”
The distribution will take a little while to activate, as it is setting up your distribution in all of the points of presence around the world. Once it completes, you will have your distribution created, but your DNS entries aren’t pointed at it yet. You shoudl be able to see the new cloudfront.net domain name in the table. You can test that in your browser now, but be aware that it will use cloudfront’s default certificate, rather than your custom one.
Next up, we need to add CNAME entries to your DNS domain so that whatever names you wanted are CNAME aliases of the cloudfront distribution. Once you’ve done that (and the changes propagate out which might take a while), your website should be live! Hooray!
Automated build and deployment
We now have a working website. We could stop here, if we wanted to. It would be relatively easy to run hugo on your laptop every time you need to make a change, log into the AWS console, upload the new content to S3. But that’s a lot of things to do. What would be easier is setting it up so that whenever we push changes to github, AWS automatically detects the change, rebuilds the content, and uploads to S3.
There’s another advantage to taking this approach too. Cloudfront is a caching CDN. This means that if you update the content, the edge POPs that serve up the content will continue to serve up their cached data until the expiry happens. By default, this is set to a day so it would take ages before your content would update on the web. To work around that, Cloudfront has a feature that allows you to invalidate part or all of the cache. You could manually perform the invalidation each time, but that is yet another step to remember.
Enter CodePipleline. Code Pipeline is a continuous integration build system that listens for changes on your code repositories, then builds and deploys those changes without your intervention. In our case, the pipeline is very simple, and doesn’t need any validation steps.
To set up code pipelines, here’s what we do:
- Make sure your hugo website is in a supported code repository. AWS offers CodeCommit, but almost everyone (including me) uses GitHub. Get your code all into a repo there. It can be either public or private.
- Add a file to your repo that tells CodeBuild (a sister product to CodePipeline) how to build the code, and where the artifacts are. The file is called
buildspec.ymland should be at the top level of your repoThe documentation for specfiles is located here, but its fairly intuitive. You give it a bunch of “Phases” that are executed in order, and then you tell it where the built artifacts will be created. In this circumstance, we install hugo into the build environment, then run it. The one odd thing we’ve had to do was add the ananke theme directly, as codepipelines does not support submodules.version: 0.2 phases: install: run_as: root runtime-versions: golang: 1.13 commands: - wget -nv -O /tmp/hugo.deb https://github.com/gohugoio/hugo/releases/download/v0.58.3/hugo_0.58.3_Linux-64bit.deb - dpkg -i /tmp/hugo.deb - hugo version pre_build: commands: - mkdir -p themes - git clone https://github.com/budparr/gohugo-theme-ananke.git themes/ananke - mkdir -p public build: commands: - hugo artifacts: files: - '**/*' base-directory: public - Now we can configure our pipeline. Back we go to the console, and into the “CodePipeline” section in “Developer Tools”
- Click on “Create Pipeline” in the top right.
- Give your pipeline a name, and let it create a new service role for your pipeline. This is needed to give the pipeline the permissions it needs to build the website. Click on Next
- Set up your source repository - This may require you to authenticate with github.
- In the “Build - optional” phase, we want to use CodeBuild. You’ll need to create a CodeBuild project using the “Create Project” button. This will pop up a new window. You can choose defaults for all of this. I chose Ubuntu for the operating system and the standard:2.0 image. You will need to create yet another role for execution.
- For the deployment provider, choose Amazon S3, and select your website bucket. You should also select “Extract file before deploy”
- Create the pipeline, and make sure that it runs all the way through, and updates your S3 bucket.
Once this completes, your pipeline will run each time a new change is detected in github. But we’re still missing the cache invalidation. To add this, we want to add another step to the “Deploy” phase of the pipeline.
- Click “Edit” on your pipeline
- click “Edit stage” on the deploy stage
- click “Add action group at the bottom of the stage. This will pop up a dialog
- Call the action whatever you want. I used “invalidateCache”
- Choose “AWS Lambda” as the action provider. Lambda is a way to execute code in various steps of your cloud infrastructure without having to provision servers.
- This will then show you a bunch more options - But we need to create the lambda first. In another window, open the console back up and go to “Lambda” under “Compute”
- click on “Create function”
- Type in your fucntion name, and click on “Choose or create an execution role”. We can leave it as “Create a new role with basic lambda permissions” for now, although we’ll need to give the lambda permission to call cloudfront later.
- Create the function. This will take you to the lambda editor page.
- Use the following code for your lambda:
This is a little code snippet that calls cloudfront to create the cache invalidation, then it notifies pipelines that it is done. In the event of a failure, it notifies pipelines of that too.
var AWS = require('aws-sdk'); exports.handler = async (event, context) => { console.log("Event is ", event); console.log("Context is ", context); try { var codepipeline = new AWS.CodePipeline(); var cloudfront = new AWS.CloudFront(); var jobId = event["CodePipeline.job"].id; var distributionID = event["CodePipeline.job"].data.actionConfiguration.configuration.UserParameters; console.log(`Invalidating distribution ${distributionID} using ${context.awsRequestId}`); await cloudfront.createInvalidation({ DistributionId: distributionID, InvalidationBatch: { CallerReference: context.awsRequestId, Paths: { Quantity: 1, Items: [ "/*" ] } } }).promise(); await codepipeline.putJobSuccessResult({ jobId: jobId }).promise(); } catch (ex) { await codepipeline.putJobFailureResult({ jobId: jobId, failureDetails: { message: JSON.stringify(ex), type: 'JobFailed', externalExecutionId: context.invokeid } }); } }; - Save the lambda function. Now we need to give it permission to call cloudfront. To do this, we need to go to “IAM” in the “Security, Identity, & Compliance” section.
- Click on roles, then find the role for your lambda function. It should be named the same name as your lambda function, with -role- and some random gibberish after it. Click through
- There should be one policy attached to the role. click on it, then click the “Edit Policy” button. I use the JSON editor.
- Copy and paste this:
Making sure to replace your own account number and regions in the logging entries. This policy has 4 rules in it. The first two are standard rules that allow it to create logs to show you that it is working. The third rule allows it to call back to pipelines to set the status of the job. The last rule allows it to call the CreateInvalidation operation on cloudfront.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "logs:CreateLogGroup", "Resource": "arn:aws:logs:ap-southeast-2:855806831918:*" }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:ap-southeast-2:855806831918:log-group:/aws/lambda/invalidateDistribution:*" ] }, { "Action": [ "codepipeline:PutJobSuccessResult", "codepipeline:PutJobFailureResult" ], "Effect": "Allow", "Resource": "*" }, { "Action": [ "cloudfront:CreateInvalidation", "cloudfront:GetDistribution" ], "Effect": "Allow", "Resource": "*" } ] } - Review and save, then return to your original window, where you’re setting up the build action for your pipeline.
- Select your lambda from the drop down (you might need to refresh using the button to the right)
- Put in the distribution ID of your cloudfront distribution as a parameter. That way you can use the same lambda for multiple websites/distros.
- Done.
Now you have invalidation as part of your pipeline, as well as building. Click “Release change” to run the pipeline again from the top, and make sure it goes all the way through.
Phew, we’ve got there.
Where to from here?
This isn’t the end of this story. This post shows you how to set up a static website with auto-deployment manually, using the console. In a subsequent post I’ll show you how to automate the automation, removing all those manual steps you had to run. I’ll use CloudFormation and CDK to automate the creation of all of these resources.
-
disclaimer: I am an Amazon Web Services employee. All content posted here is my own opinion, and is not official AWS documentation ↩︎